Light Field Segmentation 基础知识
所谓4-d的light field 图像,就是不仅有光强度信息,还有光的direction,即角度信息,详见维基 light field camera.因此原来只需要用 $(x,y)$ 就能描述的图像,现在需要加上“视角信息”,即, $(u,v,x,y)$
如图所示:
本文干了啥
- 分割问题很复杂,数据量大,还有redundancy(不同视角的同一个事物),因此作者建立一个graph,这个graph基于super pixel建立,并且将super pixel作为基本处理单元,从而减少了计算量
- 用户需要指定一些label,具体怎么指定的我也没看清楚,应该是像图2 所示的随便画几条线?,反正没写明白。然后利用这些label进行分割。主要是利用有label数据提供的距离信息。
具体做法
首先是按照下图的pipeline,建立graph,然后用graph cut得到最终的分割结果
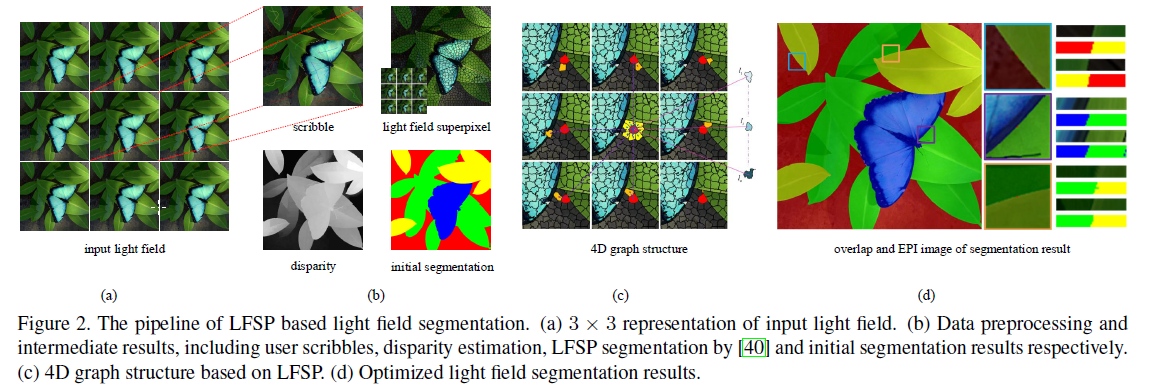
注意看有label的那张图即scribble上面有几条线,应该就是用户的input了,
disparity那张图其实是light field 的一个经典特征,在related work中提到,本文使用文献
Occlusion-model guided antiocclusion depth estimation in light field IEEE Journal of Selected Topics in Signal Processing, 2017
的算法进行计算(还是同一批作者)
super pixel是根据文献
4d light field superpixel and segmentation.CVPR 2017 (同一批作者),
做的
然后基于已经得到的scribbles, disparity and LFSP,就得到了 初始分割结果(咋得到的?),见b图。
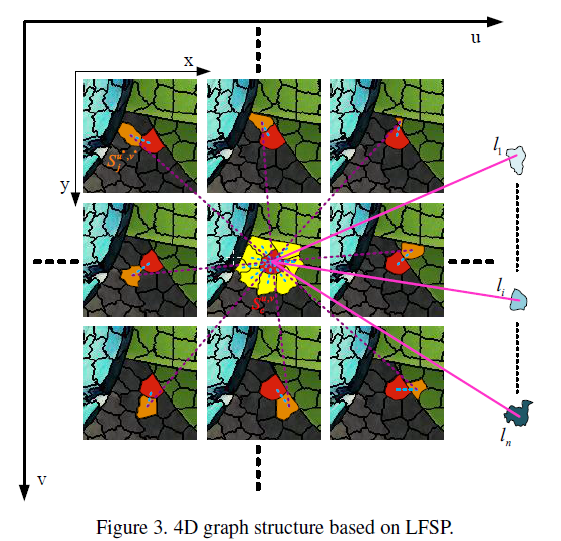
然后建立4D graph structure,如图3.
lfsp
就是super pixel了,加了light field的限制而已。
令 R 为具有相似特征的一块3d区域, 一个light field记为$L(u,v,x,y)$, 而 super pixel记为 $S_R(u,v,x,y)$,
那么就可以定义为:
\({S_R}\left( {u,v,x,y} \right) = \bigcup\limits_{i = 1}^{\left| R \right|} {L\left( {u_{P_i},v_{P_i},x_{P_i},y_{P_i}} \right)},\)
图结构
根据disparity信息,即 $d(p)$ 以及坐标关系得到super pixel的邻域(公式2),进而根据邻域得到两个 super pixel是否连接的信息(公式3),即,若两个super pixel的欧式距离小于某一个阈值,那么就认为是连接的,至于公式3的大P是啥,不知道啊,哦大P在公式8里也有,公式8周围也只是说是position information,哦,是 cielab色彩空间 的channel。
最后的图结构如图3所示。
能量函数
对于公式6:
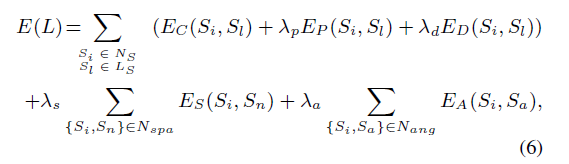
前三项分别是color position and disparity information of LFSP $S_i$.
具体式子就是公式8了。
目测上面图结构的作用就是方便公式6的加和?
联合公式7和8,有很多加法运算。
后两项的smooth term为了保证相邻像素的segmentation一致。
能量函数的优化
根据文献
Y. Boykov, O. Veksler, and R. Zabih. Fast approximate energy minimization via graph cuts. The Proceedings of the Seventh IEEE International Conference on Computer Vision, pages 377–384 vol.1, 2002.
的 $\alpha$-expansion 算法来解公式6。
最终算法如下:

作者在最后一段提到
user inputs are propagated to LFSP and some LFSP are labelled as seeds in the 4D graph
难道如果这个super pixel的一部分被label了,那么这个super pixel也就被label了?
思考
杂谈
哎,cv圈的文章看着好累,以后再也不看cv圈的文章了。
一般都是点到为止,叙事风格好奇怪,很多关键的东西一笔带过,留下的只是很生硬的步骤。
正事
根据我的理解,话说本文的关键应该是如何根据user的少量的input label(即scribble)对整个image进行分类的
即,如何根据少量的label进行分类。
但硬生生被描述成了普通分割问题,重点都错了啊。