摘要
有很多算法都能从无类标数据learn深度层次性feature。
Kmeans也能提特征,优点是快啊,还能large scale啊
这篇文章介绍了kmeans这种用法的一些tricks
话说我以前没接触过kmeans的这种用法哈
Intro
ML的一个主要目标就是为其他task学习deep hierarchies of features。
Kmeans的形式稍微变一下,就很容易看出来它能够学习到feature了:

此时,类标 $s^i$ 就是数据点 $x^i$ 的new representation,注意此处 $s^i$ 是 $k$ 维的。
即,有多少cluster,变换后的特征就有多少维度。
正文
首先是预处理和初始化,
由于每一个data point 只对一个centroid有贡献,因此data一定要多啊。
还要normalization,即whitening transform,除了减去均值除以标准差这种之外,还可以用ZCA白化变换
初始化。对于非常scalable的实现来说,出现一些cluster只有很少的点,也没事,只要扔掉这些cluster就行了。
实际上,一般随机初始化就够了。
为了更稳定地更新centroid,可以采用damped updates of the centroids,总的框图如下:

用于图像识别
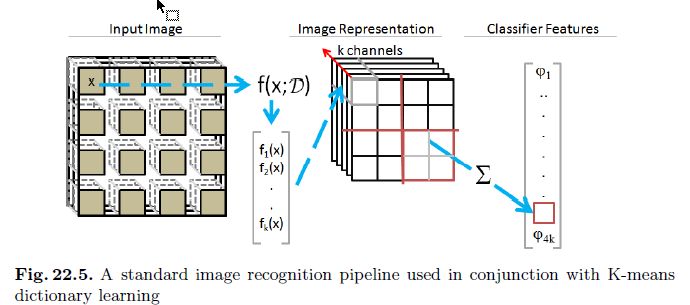
重申此处 $s^i$ 是 $k$ 维的。中间图一般还得池化一下(即pooling,简单的就是平均一下,和CNN很像了)
结论
也就了解了一下kmeans做特征提取的大概流程。