前言
一篇 arXiv:1706.05048。
此文和我的一个idea重了,同样的出发点,只是作者没有明说。
其实就是将分类器弱化使用。
分类器既然能够识别出来object的具体位置,当然可以用来聚类,此时其label信息当然也可以弱化(这个label的使用我没有作者想的多)。
说到底这种用法就是作弊吧,就是利用有监督信息来学习representation。
另外一个和我相同的点:利用CNN的shape识别功能,学习到cluster的shape信息,进而对有overlap的shape也能区分开来。
摘要,Intro以及 Related work
作者完全在扯淡,哈哈
你用label信息学习到了cluster的形状信息,bp之后得到了好的representation。
只是你碰巧使用DNN来做的,你就说DNN的一些特性值得借鉴,如:
suggest that hierarchical frameworks that progressively build complex patterns on top of the simpler ones (e.g., convolutional neural networks) offer a promising solution
细想一下,这个层次组织结构(the hierarchal organization of the visual ventral stream)的确值得用,但原因并非此文所言。
作者声称此为generic clustering,但明显不是嘛,你CNN对2-d的image的结构能hold住,能搞定一般的多维data么?很明显不行的吧
目前的深度聚类分为两大类,要么直接聚类,要么专注于学习representation。
细节
网络结构:
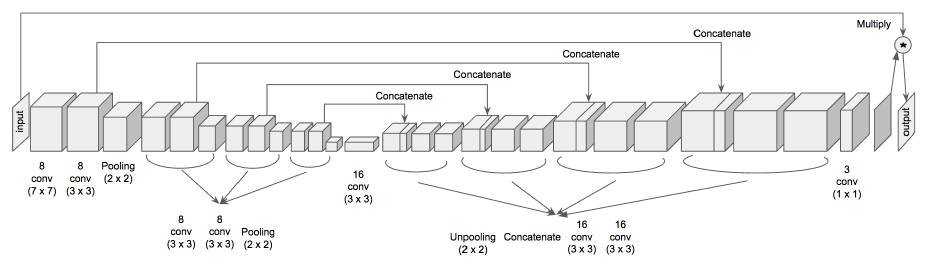
输入:

注意,input是由各种shape的cluster组成的,这些cluster生成的时候有很多参数是随机的,如密度,scale,以及旋转角度都是随机的,然后再将其转化为image,即有点的地方是1,没点的地方为0.
这样,网络结构的output就可以理解了,需要将其与input相乘,再去计算误差。
不过,作者说的用随机梯度下降来optimize a clustering objective,具体不知道怎么做的,又提到用:
mean squared error loss and train the network with the Adam optimizer [31]. Batch size is set to 16 and learning rate to 0.001
既然这么说了,估计就是直接用label做mse?
至于Evaluation metric,作者自己搞了个,即,给定n个点,搞出一个 $n^2$ 的矩阵,表明每两个点是否处于同一个cluster中,然后从模型输出也搞出一个类似的矩阵,再算这俩矩阵的汉明距离。
最后效果还不错。