普通SSC
首先是Sparse Subspace Clustering:
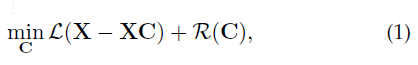
我们的目的是学习到 $C$ ($R^{n\times n}$) ,即 linear representation of the input $X$ ($R^{d\times n}$)
$d$ 是data的维度, $n$ 是数据个数。
得到了affinity matrix,就可以通过applying spectral clustering得到clustering results。
更具体一点,就是
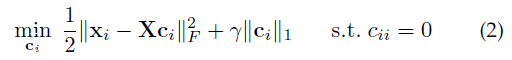
ssc的稀疏体现在,要用一部分other samples 来 linearly reconstruct $x_i$。
以上优化可以用alternating direction method of multipliers (ADMM)来解。
Deep Subspace Clustering
这个就更复杂一点,但形式还是没啥大变化:

也就是将线性重构变成了非线性重构
其中
SSC, each sample is encoded as a linear combination of the whole data set
那么现在就是非线性组合了吧。
另外,这一项
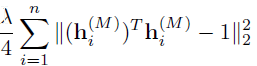
用来避免trivial解,如 $H^(M)=0$.
整体结构图:
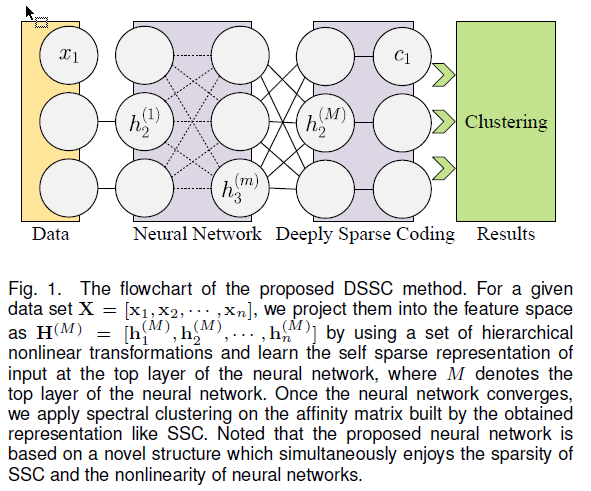
至于优化,就是先固定 $c_i$ 和 $H_i^(m)$ , 优化 $\Theta$ (网络参数),然后固定 $\Theta$,优化$c_i$ 和 $H_i^(m)$
感受
其实就是将聚类的目标函数和NN的目标函数融合在一起,正如Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering中为了避免trivial解而用decoder重构输入类似,本文也做了类似的重构工作,只是ssc本来就带重构,因此就没那么明显了。
不过,由于dssc重构的是输出层,因此还需要另外显示地避免trivial解,即在目标函数中增加: