总括
作者声称能得到一个K-means-friendly Spaces,是因为将kmeans的目标函数加入到了loss中,并且通过decoder重建输入信号从而避免了trivial解。
所谓 ‘K-means-friendly’ 指的就是
evenly spread around some centroids
评价
通过 DNN 来聚类的文章很多,一个很critical的问题就是如何避免trivial解
在 Deep Sparse Subspace Clustering 中,强制网络输出层的范数接近1,
在Unsupervised Learning by Predicting Noise中,通过拟合随机噪声来避免trivial解。
本文条件更强一点,即重构输入。
细节
具体流程不说了。
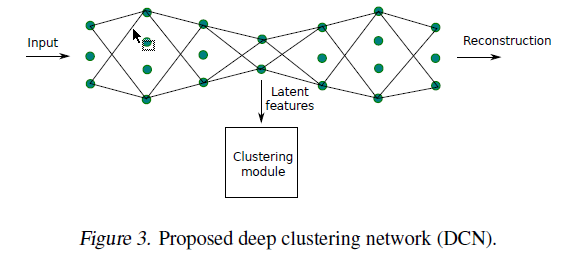
简要回顾一下:在encoder的输出端,我们认为网络学习到了很好的representation,在这一层做kmeans,为了避免trivial解,网络继续延长,即搞一个相应的decoder来重构输入。
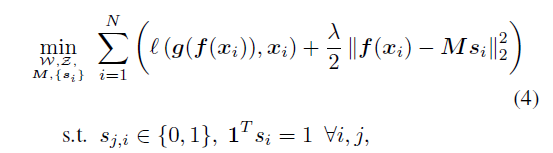
其中第二项是kmeans的目标函数,第一项的 $f$ 指的是encoder, $g$ 是decoder。
$\lambda$ 是正则化参数。
结构图: